
学了python不知干啥?爬爬虫!(5)requests库的使用+错误处理
多线程批量翻译
合理爬取,不恶意扩大站点压力
本文章仅作示例,请勿用作非法用途
本篇并没有完成实际项目,而是讲述更加普遍化的处理方式。如果只是希望复制粘贴的,现在可以选择离开了
Requests初探
在前几次的爬虫中,我们一直使用urllib来完成需求;今天我们尝试一个新的第三方库:requests
在它的官网中,对它有如下介绍
Requests 完全满足今日 web 的需求。
Keep-Alive & 连接池
国际化域名和 URL
带持久 Cookie 的会话
浏览器式的 SSL 认证
自动内容解码
基本/摘要式的身份认证
优雅的 key/value Cookie
自动解压
Unicode 响应体
HTTP(S) 代理支持
文件分块上传
流下载
连接超时
分块请求
支持 .netrc
不需要全部看懂,总之只需要知道:很强、很易用就对了!
- 要学习requests库的基本用法,您可以点击这里来查看官方文档*
小试身手
最近2077很火,我们就去贴凑个热闹,看看大家对他的讨论
这里就是本次我们要爬取的目标啦
使用之前要用pip安装
1 | pip install requests |
先写一个最简单的get请求看一看?
1 | import requests |
从上面的代码不难发现,使用requests请求非常简单。事实上,对于常见的请求类型,requests都提供了简单的方法
1 | r = requests.put('http://httpbin.org/put', data = {'key':'value'}) |
接下来,通过使用.text方法,我们可以直接获取到对应源代码,requests会自动根据内容推断对应编码并完成转换的过程。
当然,如果你希望手动指定编码,也是可以的
1 | response.encoding = 'ISO-8859-1' #手动更改编码 |
那么这样是否就可以获取到我们想要的内容了呢?答案很残酷:NO!
既然简单的不行,那么加点请求头试试看?
在requests中,加入请求头的方法也十分简洁,只需要设置headers参数即可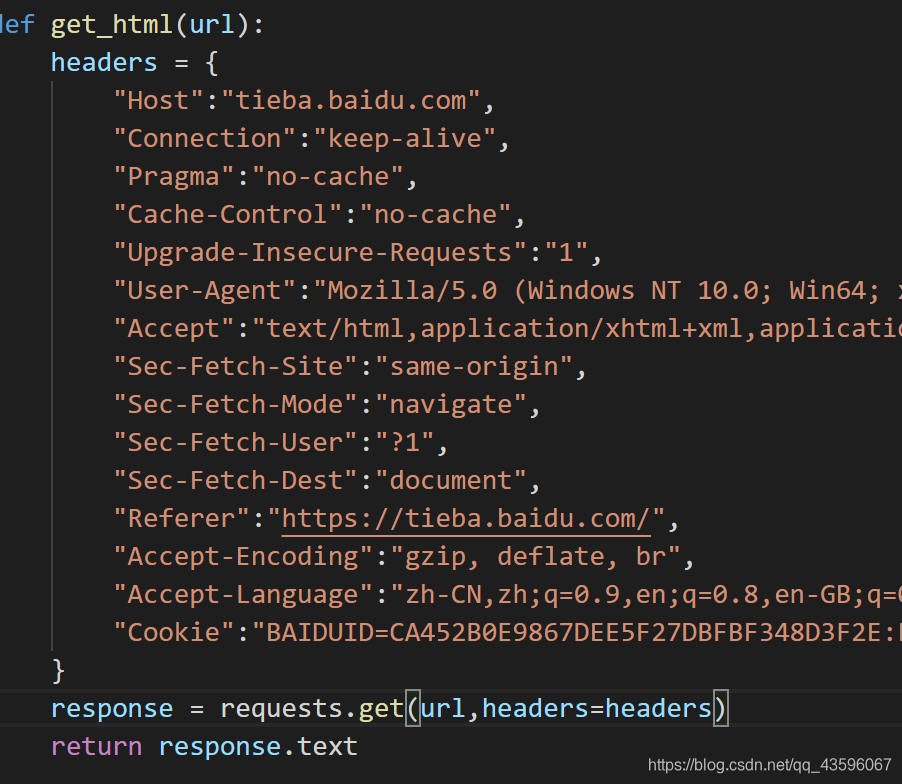
但这个时候报了一个很奇怪的错
查了查,发现是Cookie里面有拉丁文字符
把它删了后,再爬一次当当当当!依然获取不到 ~
(按理说百度贴吧应该是个静态页面,而且比较容易获取到,进行到这一步的时候我也很绝望,看来是升级了……)
当你print结果的时候,你会发现输出并没有你所需要的;但是,当你将结果写入文本再打开时,你才能看见全貌
(cao!!!)

既然爬取到了,那么就可以进行后续的解析和保存工作了。这一部分前面已经讲过不少,这次就不赘述了。
而这次我们要关心的,是爬取的过程,是否已经完美无缺了?答案很显然,不是。
异常处理
HTTP状态码
让我们回到这个response
Response有一个属性:status_code,用来告诉你这次访问的情况,如果一切顺利,那么它的值会是200,就像下面这样

在以往的教程中,我们一直假定一切安好,而没有考虑过不安好的情况。这在一个完备的爬虫程序中,很明显是不可取的。那么接下来,我们就要好好考虑一下了。
什么是HTTP状态码呢?
当浏览者访问一个网页时,浏览者的浏览器会向网页所在服务器发出请求。当浏览器接收并显示网页前,此网页所在的服务器会返回一个包含HTTP状态码的信息头(server header)用以响应浏览器的请求。
下面是常见的HTTP状态码:
-200 - 请求成功
-301 - 资源(网页等)被永久转移到其它URL
-404 - 请求的资源(网页等)不存在
-500 - 内部服务器错误
如果发送了一个错误请求(一个 4XX 客户端错误,或者 5XX 服务器错误响应),我们可以通过 Response.raise_for_status() 来抛出异常:
1 | bad_r = requests.get('http://httpbin.org/status/404') |
而当其为200时,调用该方法则什么也不会发生
请求时间
另一个值得注意的点是请求时间,对于大批量爬虫,如果因为服务器问题让部分爬虫长时间未得到响应而使主程序一直僵持,产生的结果是难以预料的。所以,应当有必要设置一个阈值,使得链接在超过这个时间仍然没有响应后自动断开。
对应的方法,是设置timeout
1 |
|
此处设置的timeout为0.001秒,以模拟超时连接时发生错误的情况;实际项目中,应该按需要设置
注意
timeout 仅对连接过程有效,与响应体的下载无关。 timeout 并不是整个下载响应的时间限制,而是如果服务器在 timeout 秒内没有应答,将会引发一个异常(更精确地说,是在 timeout 秒内没有从基础套接字上接收到任何字节的数据时)
在考虑了上述的因素之后,我们的代码应该写成:
1 | import requests |

这样,程序才会有良好的健壮性。
其他
- 我的水平不高,所讲之处难免有所漏洞,还望指正
- 系列文章完整目录
 wechat
wechat alipay
alipay


