合理爬取,不随意扩大站点压力
本文章仅作示例,请勿用作非法用途
前言
最近有朋友向我请求帮助,问我可不可以帮忙爬一下有度小说网的 (这不是广告!这不是广告!这不是广告! )完本小说,刚好有空我就试了一下。于是就有了此篇。
本篇可以算是学了python不知干啥?爬爬虫! (2)爬取网络小说全本并保存的另一个例子吧,所用到的基本思路都是一样的,想知道为什么这么写的朋友可以翻一下那个链接,一点一点分析的。
本篇就不费话了,直接上代码
库 本身 完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
| """
Copyright @FunnySaltyFish
Python 3.7
"""
import urllib.request as ur
import re
import os
class YouDu:
def __init__(self,start_url,save_path):
self.START_URL = start_url
self.SAVE_PATH = save_path
self.BASE_URL = f"https://www.yoduzw.com/"
def get_html(self,url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36 Edg/83.0.478.61'
}
request = ur.Request(url=url, headers=headers)
html = ur.urlopen(request).read()
return html.decode('utf-8')
def parse_html(self,html):
pattern_content = re.compile(r'<a href="javascript:" style="-webkit-tap-highlight-color:rgba\(0,0,0,0\);pointer-events:none;">(.+)</p></a>',re.S)
content = str(re.findall(pattern_content,html)[0])
if '<p style="font-weight: 400;color:#721f27;">(本章' in content:
content = content.replace('<p style="font-weight: 400;color:#721f27;">(本章',"")
if '未完)' in content:
content=content.replace('未完)','')
content = str(content).replace("<p>"," ")
content = content.replace("</p>","\n")
content = content.strip("\n\t ")
return content
def find_next_page(self,html):
pattern_next_page = re.compile(r'var url_next="(.+?)"')
next_page = str(re.findall(pattern_next_page,html)[0])
return next_page
def find_title(self,html):
pattern_title = re.compile(r'<h1>(.+)</h1>')
title = str(re.findall(pattern_title,html)[0])
return title
def get_base_url_num(self):
pattern_base_url = re.compile(r"https://www.yoduzw.com/book/(.+)/.+")
base_url_num = str(re.match(pattern_base_url,self.START_URL).group(1))
return base_url_num
def createFolders(self, save_path:str):
parent = os.path.dirname(save_path)
if not os.path.exists(parent):
os.makedirs(parent)
def get(self):
url = self.START_URL
i = 1
f = open(self.SAVE_PATH, "w+", encoding="utf-8")
while True:
print(url)
html = self.get_html(url)
content = self.parse_html(html)
next_page_text = self.find_next_page(html)
title = self.find_title(html)
text = f'\n{title}\n{content}\n'
f.write(text)
if next_page_text != "":
url = self.BASE_URL + next_page_text
else:
f.close()
break
if __name__ == "__main__":
youdu = YouDu("https://www.yoduzw.com/book/4869/349727.html","D:/Text/明朝那些事儿——1.txt")
youdu.get()
|
您可以直接修改最下方的网址(必须是有度里面的具体某一章)和保存位置直接运行此代码。

当然,给别人用不能这么直接给,所以我又简单包装了一下。
GUI 包装版
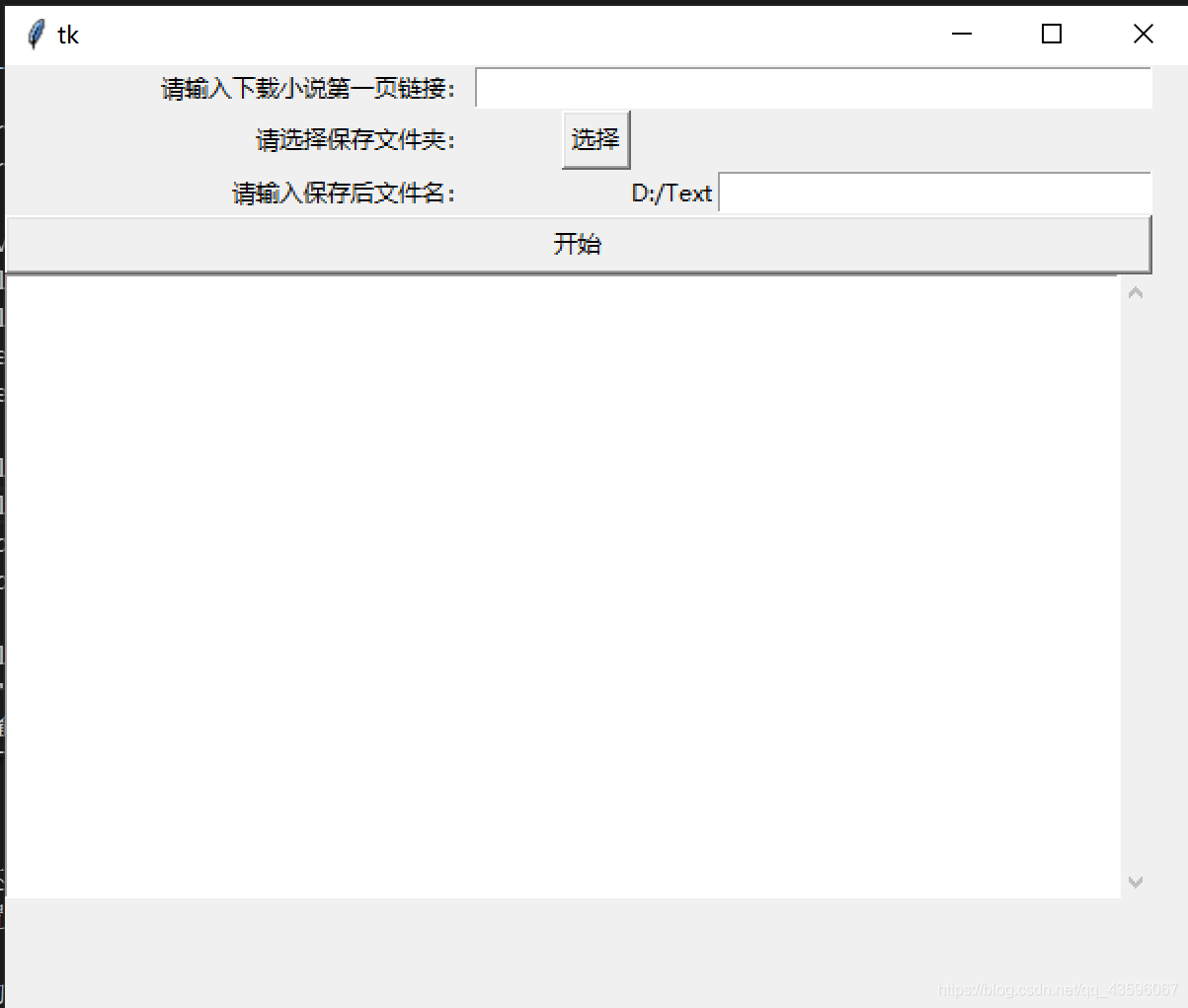
基于tkinter和简单的多线程更新写出了下面这个(丑陋的)GUI 界面
运行起来是这样的
它的代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
| import youdulib
from tkinter import *
import tkinter as tk
import tkinter.filedialog as tf
import tkinter.messagebox as tm
import tkinter.scrolledtext as ts
import threading
import queue
import sys
SAVE_PATH = "D:/Text"
class ReText(queue.Queue):
def __init__(self):
queue.Queue.__init__(self)
def write(self, content):
self.put(content)
msg_queue = ReText()
def update_message():
while not msg_queue.empty():
content = msg_queue.get()
label_title.insert(tk.END, f"正在爬取:{content}\n")
root.after(100, update_message)
def choose_save_path():
global SAVE_PATH
SAVE_PATH = tf.askdirectory()
if(SAVE_PATH == ""):
SAVE_PATH = "D:/Text"
var_save_folder.set(SAVE_PATH)
def start():
try:
youDu = youdulib.YouDu(
start_url=var_start_url.get(),
save_path=f"{var_save_folder.get()}/{var_save_name.get()}.txt")
url = youDu.START_URL
f = open(youDu.SAVE_PATH, "w+")
while True:
html = youDu.get_html(url)
content = youDu.parse_html(html)
next_page_text = youDu.find_next_page(html)
title = youDu.find_title(html)
text = f'\n{title}\n {content}\n'
msg_queue.write(title)
f.write(text)
if next_page_text != "":
url = youDu.BASE_URL + next_page_text
else:
msg_queue.write("爬取完成!")
f.close()
break
except Exception as e:
msg_queue.write("发生错误:"+str(e))
print(e.with_traceback())
def command_button_start():
t = threading.Thread(target=start)
t.start()
msg_queue.write('开始爬取!')
if __name__ == "__main__":
root = Tk("YouDu 小说下载")
root.geometry('600x480')
var_start_url = StringVar()
label_url = Label(root, text="请输入下载小说第一页链接:")
label_url.grid(row=0, column=0, sticky=E)
entry_url = Entry(root, textvariable=var_start_url)
entry_url.grid(row=0, column=1, columnspan=2, sticky=E+W)
label_save_path = Label(root, text="请选择保存文件夹:")
label_save_path.grid(row=1, column=0, sticky=E)
button_choose_path = Button(root, text="选择", command=choose_save_path)
button_choose_path.grid(row=1, column=1)
label_file_name = Label(root, text="请输入保存后文件名:")
label_file_name.grid(row=2, column=0, sticky=E)
var_save_name = StringVar()
var_save_folder = StringVar()
var_save_folder.set(SAVE_PATH)
label_path = Label(root, textvariable=var_save_folder)
label_path.grid(row=2, column=1, sticky=E)
entry_file_name = Entry(root, textvariable=var_save_name)
entry_file_name.grid(row=2, column=2, sticky=E+W)
button_start = Button(root, text="开始", command=command_button_start)
button_start.grid(row=3, column=0, columnspan=3, sticky=E+W)
var_title = StringVar()
label_title = ts.ScrolledText(root)
label_title.grid(row=4, column=0, columnspan=3)
root.after(100, update_message)
root.mainloop()
|
撒花!
其他
- 我的水平不高,所讲之处难免有所漏洞,还望指正
- 因网页结构变动等原因,此项目源码可能无法直接运行,如遇此情况请自行酌情修改!!!
后续




 wechat
wechat alipay
alipay

